Editor’s note: This is part two in a three-part series that explains machine learning for content automation. Read part one here.
It can be challenging, if not impossible, to make sense of the seemingly infinite amount of customer data available to your business. Leveraging machine learning to enable content automation can help you and your content team make sense of this data, which increases content effectiveness.
If you haven’t quite mastered machine learning as it relates to content automation, you’re not alone. Plenty of companies have yet to take the plunge because they don’t understand the methodology behind machine learning and content.
So, what steps do you need to take to use machine learning as you automate and personalize content delivery? In part one of this series, we covered the foundational elements you need to start the process. In this piece, we’ll get into the “how” of machine learning as it relates to content, and the steps you need to take to leverage your data to provide a personalized experience for your users.
So, let’s jump right in.
Step 1: Get the Right Team in Place
To begin automating and personalizing content, you’ll need to ensure four important roles within your team are working together. Keep in mind that in some companies, one person may fulfill more than one of these roles.
Your content engineer is the first and most important person you’ll need in place to establish a system of content automation and personalization. A content engineer helps define and facilitate content structure during the content strategy, production, and distribution cycle.
Your content engineer will undertake many tasks to enable content automation and personalization, from structuring and modeling the metadata covered in our previous piece to developing audience and session-based analytics personalization rules and scoring. The content engineer is also the point person for all decisions related to database architecture, content management, and content delivery.
Of course, what your content engineer is really trying to bring to life is your content strategy, which leads us to the second team member crucial to this process – the content strategist. Your content strategist will help your content engineer understand how your content supports important business objectives. To get the most value out of content automation, content strategists must ensure that the data you collect on your users supports your understanding of your customer personas, and that the content is pushing those customers towards behaviors that provide value to your organization.
The third necessary role to maximize the value of content automation is a content analyst. Your content analyst should be familiar with how content and user data is collected, and be able to translate that data into meaningful insights for your company. Your content analyst should also measure outcomes to ensure that your automated content delivery is providing appropriate value. Finally, the content analyst is the person who reports outcomes of the delivery process: which content is driving valuable behaviors and which is not, and using that data to support the content engineer’s decisions about how to optimize the content delivery system.
The final position you need to ensure is in lockstep with the rest of your automation team is the content designer. For automated, personalized content to really appear seamless, it needs to be designed to support the delivery process.
Now let’s take a look at some of the design principles that support automation.
Step 2: Design Your Content for Automation and Personalization
There are three important design practices that will help support your goal of automating personalized content.
Practice A – Utilizing Components
The most important design element to consider when implementing content automation is ensuring that your content is responsive to specific users’ needs. This means that your website – and all the pages on it – needs to be laid out to accept varied content assets on a single page. XML data models like Darwin Information Typing Architecture (DITA), refer to these assets as “components,” which can be requested and assembled to generate personalized content on the fly.
Utilizing these components necessitates several design considerations, such as:
- Size
- Performance (e.g., loading time)
- How content type (text, video, graphics, etc.) complements your site’s layout
While that’s hardly a complete list, it’s a starting point for the component attributes that need to work together to deliver a seamless content experience. For an example of what this looks like in practice, let’s look at Sprint’s customer portal.
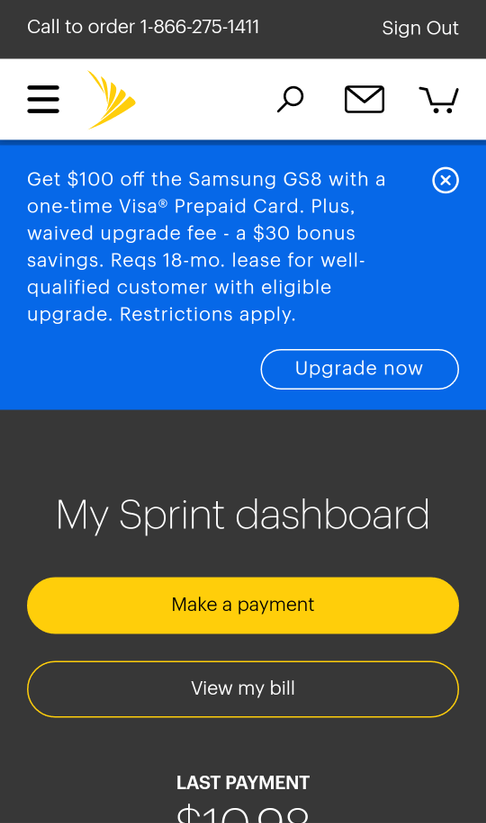

In this example, Sprint utilized a simple component to provide value to the customer, (in this case, a promotion for the Samsung G8). It integrated seamlessly with the customer’s dashboard design for users who had recently shown interest in that particular phone.
The simplicity of this component’s design makes it easy to customize. Sprint only needs to understand a customer’s recent browsing history or searches, infer intent, reference that against current promotions, and then deliver the most relevant copy (if any).
By delivering personalized offers in this manner, Sprint has drastically improved business outcomes, reducing customer churn by 10%, increasing its net promoter score by 40%, boosting customer upgrades eight-fold, convincing 40% more customers to add a new line, and improving overall customer service agent satisfaction.
What’s equally important as designing your content in components is ensuring that you’ve implemented the tags we covered in our previous article, and that these tags are tracked in your web analytics system.
 An example of content tagging in Sitecore (source)
An example of content tagging in Sitecore (source)
It’s essential that you track both the delivery of a content component and the pages on which it was delivered. You can do this by utilizing the custom variables in your web analytics platform.
Understanding how the content’s design enables your content management system (CMS) to assemble personalized content on the fly is the first step. But how can we translate that into a front-end philosophy?
Related: 5 Signs It’s Time to Change Your CMS
Practice B – Treat Every Page Like the Homepage
A key architectural philosophy you’ll need to adopt to successfully deploy machine learning-enabled content automation is treating every page on your site like your homepage.
So what does this mean, exactly? Your web analytics platform probably tells you that a sizable portion of your web visitors aren’t coming to your site via your homepage. Visitors to a site can land anywhere, which is why it’s important for each page on your site to be engineered to lead them towards an ideal outcome – both for them and for your business.
This is where user intent comes in. When a user requests a page on your website, your content delivery system will need to answer a series of questions before deciding which content components to deliver:
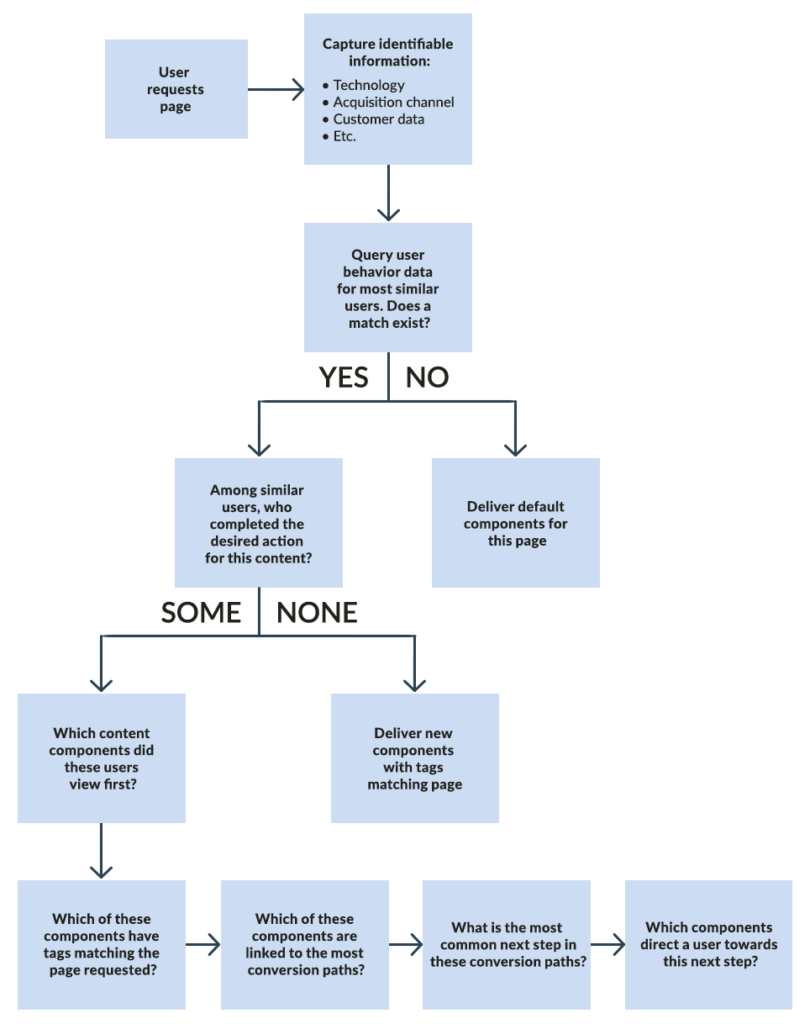
The goal of this decision tree is to deliver content to users that helps them complete their goals. Much like a homepage, every page on your site should be designed to quickly funnel users towards that content. If your business objectives are aligned with those goals, then this benefits your company as much as it does your users.
To move your users closer to accomplishing their goals, your content should exhibit the Best Next Customer Experience approach discussed in part one, which focuses on setting users on the ideal path towards valuable behaviors. Let’s take a closer look.
Practice C – The Best Next Customer Experience
To understand what the Best Next Customer Experience looks like, we need to review the data outlined in part one.
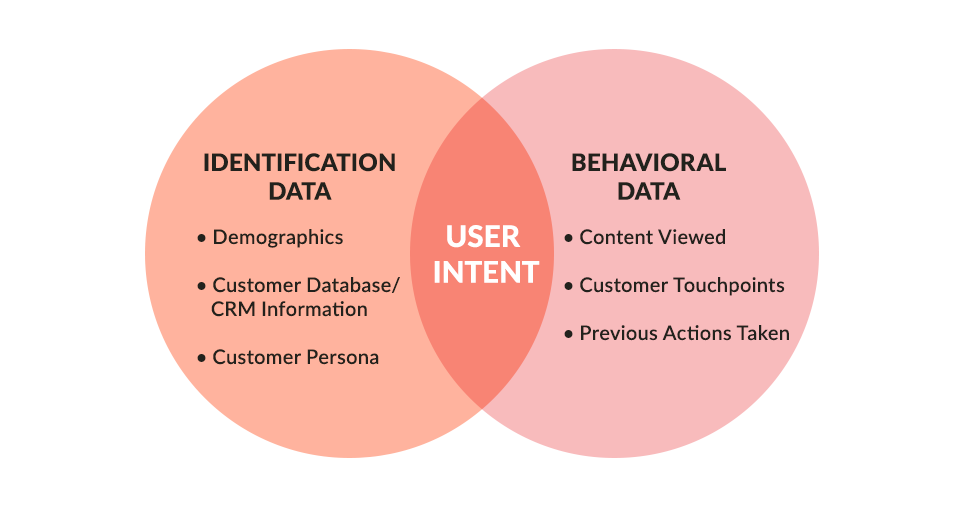

Once we understand the user’s intent and preferences, we match that with our content tags. Then, we can match the user with the content that most closely aligns with their goal, as well as the content that will most likely produce a valuable action. (This is why it’s essential for your CMS to be able to reference past performance of each piece of content, i.e. how frequently did it lead a user to exhibit a valuable behavior?)
Your content delivery system should serve the content components most likely to produce a valuable behavior given a user’s profile and past behavior. It should also perform ongoing measurement of conversion rates to ensure that it’s always generating the most optimized content for an individual user.
Now, let’s look at how your content’s design can support data, and vice versa.
Step 3: Incorporate Data Collection Into Your Design
Because a machine learning algorithm needs data to decide what content to deliver to users, it’s important to establish data collection before getting started with content automation. You can enable A/B testing on your content to ensure that your content delivery system is not relying on small sample sizes to make decisions about which content to use. Or, if a user has viewed the optimal, personalized content for a page/request and not converted, you can experiment with delivering the next-most common conversion path the next time that user returns to your site.
The notion that design should be influenced by data is still taking hold. Steph Hay, then VP of Design at Capital One, described in an interview with Fast Company how this shift is occurring within her company:
…designers are going to be working at the systems level. We’ve been primarily working at the interface and touchpoint levels so far, because that’s the flow we’re designing across channels. But now we’re also working at the system level, because the AI is going to be making decisions. The system effectively becomes the new interface. Roles like AI writer, language scientist, multi-modal or narrative designer, and data visualization designer now exist on my team and others at Capital One. The key component here is that we’re all transitioning from a largely static, reactive design environment to a dynamic, proactive one fueled by data and AI.
Effective content is driven by an understanding of the user, so let’s start with how the data you need to collect from your users.
User Data
To personalize content, your CMS needs to create user profiles based on cohort analysis. Cohort analysis is a process by which users are broken into subgroups based on common characteristics or experiences. How you define these cohorts and profiles depends on the specific questions you want to answer, and the type of content you are delivering:
- If your thought leadership content needs to meet the needs of diverse types of users, you may ask, “How can we determine which of our user personas a user fits in?”
- If you’re looking to increase engagement with your content, you might ask, “How do our user’s past content interactions help us understand who they are?”
- If your sales content is geared to increase conversions, you may ask, “How can our customer’s buying history tell us the products or services they’re likely to need in the immediate future?”
To answer these questions, you’ll need to collect as much data about your users are you can. To do this, you need a database with a unique ID for every user, which will then be associated with the CRM Contact ID, web analytics Client ID, and all other identifiers for that user.
Allowing users to log in can make this process easier by removing duplicate IDs for a single user. This also opens an interesting design opportunity by allowing the user to customize their own version of the site, incorporating only the elements and features that apply to them.
Another advantage of allowing users to create accounts on your site is that it gives you an opportunity to collect identifying information about them. You can collect everything from basic demographics like age, location, and gender, to the type of technology used, to the content interacted with, and so on. Cohorts can be defined using any collection of data points, but the more you have, the more precise of a user profile that cohort creates.
With your user data in place, you can then begin capturing behaviors.
Behavioral Data
The ultimate goal of collecting behavioral data is to determine the content that leads to valuable actions. This can take many forms – conversions, events, views of specific content, etc. – but these valuable behaviors should make a meaningful contribution to your organization’s overall objective. (For background on how to ensure that your data aligns with business goals, see our primer on content intelligence.) To capture these valuable behaviors, you’ll need to design content with measurable interactions, such as incorporating JavaScript into an interactive element to capture clicks.
Everything that leads to a valuable behavior contributes to your business goals, which is why it’s important to feed your CMS all the behavioral data that’s available. Within the same database as your customer information, you should also house tables for your web traffic, marketing automation activities, CRM, and all other data sources. Each row should correspond with an action taken – a click, a pageview, an email sent – and should include an ID that can be associated with a single user.
For your web traffic, you’ll also want a session ID that can be used to sort all actions into a single session. This allows you to have a better understanding of the timing of behaviors – does this content contribute to a valuable behavior in the same session, or is it assisting that behavior later? If the user has come to your content through a marketing tactic, you’ll also want to connect that use of the content to the marketing action with a tag for the campaign, creative, etc.
Behavioral data is extremely important in determining what a user did with your content that led to a valuable behavior, but it doesn’t answer why. For that, you can turn to perception data.
Perception Data
There are several different forms of perception data that can help you understand how your content supports your goals. Ratings, for example, can be utilized by your CMS to prioritize the delivery of certain content to your users. Incorporating a rating system into your content can be as simple as adding a widget to the bottom of each page you want to measure.
Another way to leverage machine learning to improve your content automation is to utilize natural language processing (NLP), to analyze your voice of customer data. NLP is a way for computers to analyze, understand, and derive meaning from human language. It considers the hierarchical structure of language and uses rules about the relationship of words used together in a phrase or sentence to automatically derive meaning from speech or text.
Using NLP, you can learn a lot about both your users and the specific needs they have when using your content. When analyzing voice of customer data, look for themes or trends that can more clearly define a user’s persona or profile. When identifying common themes, your CMS can use this data to inform its cohort analysis. You can also use natural language processing to analyze sentiment and understand what’s driving positive and negative experiences within your content.
A content effectiveness evaluation tool such as ContentWRX can also provide significant insight into content performance. ContentWRX provides two pieces of data that can directly influence your cohort definitions: a user’s reason for visiting the site, and a demographic self-identification that can be directly linked to a customer persona. ContentWRX can connect content and cohorts to crucial elements of content effectiveness, answering questions like:
- What users are most likely to have difficulty finding the content they need? Which content is influencing this issue, and how can your content help them get where they need to go?
- Which users are the most likely to accomplish their goals with your content? What content are they using?
Your user’s perceptions of your content can greatly influence its overall performance. As a result, perception data can be hugely informative as to whether it makes sense to deliver a piece of content to a certain user. Now, let’s take a high-level view of the process of setting up a CMS to enable personalization.
Step 4: Select and Set Up the Right Content Technology
Your site needs to deliver the right content to the right user at the right time. That’s why having your content technology fully integrated with your customer and analytics database is so important.
To do this, your CMS needs to understand how your content is performing and who your users are. And if the performance of your content or user cohort definitions begins to shift, your platform needs to be able to update the relationship between components and users on the fly.
Once you’ve selected and begun setting up your new content technology, you’ll need to configure the personalization settings for your content. This requires establishing rules for your content and users. You’ll need to define:
- The data points in your user and behavioral database tables that determine a user’s profile
- The tags associated with your content that indicate content is relevant to a user profile
Depending on the purpose of your content, these rules can be simple or very complicated. For example, an internal portal for your company’s employees may reference the user’s department and match that field to content tagged for that department. Other rules may reference a wide variety of data, from engagement with and perception of content, to a wide variety of user data such as age and location.
Your content strategist will define the intended audience for each particular piece of content and what specific business objectives this content supports, while the content engineer will utilize either the WCM’s wizard or an XML editor to write these rule definitions.
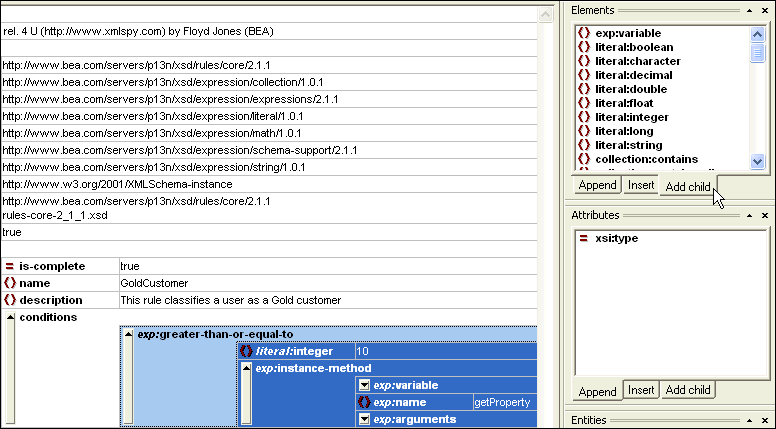 An example of rule definition in an XML editor establishing the behaviors that define a specific user profile.
An example of rule definition in an XML editor establishing the behaviors that define a specific user profile.
To understand how the WCM platform delivers automated, personalized content in real time, you need to understand a couple of foundational machine learning concepts. Let’s start with the stable marriage problem.
The Stable Marriage / Partnership Problem
First studied by David Gale and Lloyd S. Shapley in 1962, the “stable marriage” problem presents a situation in which there is an equal number of people searching for a partner. Each person has a hierarchy of preferred partners, but one person’s first choice might not fully return the favor. You might be my first choice as a partner, but your first choice might be someone else. And I’m actually your third choice.
To automate this process, Gale and Shapley developed the Gale-Shapley algorithm, which sees a team of partners propose in rounds and members of the other team provisionally accept. Engagements are finalized or broken until each person is placed into the most stable partnership.
This algorithm can also be applied to personalizing content. Think of your user cohorts as the one set of spouses, and your content components as the other set of spouses. A user requests a piece of content, and their preference is determined by his intent (informed by the data collected about the user specifically and other users like them). However, each piece of content also has a preference based on performance across customer personas, journey stages, sequences of content, technologies, and demographics. Basically, what has garnered a desirable outcome in the past.
How the WCM platform applies this algorithm is based on the personalization rules established during setup. To ensure that these personalization rules are being followed, the content analyst should review the content delivered to different user profiles to ensure no irrelevant or mismatched content is being served.
To automate preference hierarchy for content, the WCM platform must utilize another foundational principle in machine learning. This is where association rule learning comes in.
Association Rule Learning
Association rule learning is a method for automated determination of the content most likely to contribute to valuable outcomes. This method identifies the relationship between variables in large databases and has uses beyond matching user intent to content tags.
This method can be used to link conversions of distinct types: if a user has purchased from you before, what content was of interest to other customers of the same product? How do past support experiences anticipate future problems, and what content helps users resolve those issues? By using this rule to match content to the user profiles who contributed valuable behaviors, your WCM platform can create a preference hierarchy for your content.
A user profile’s hierarchy is informed by the specific request for content and the design elements we touched on earlier. Depending on the level of personalization within your content, your WCM platform may also consider things like the user’s location, the time of day, even the weather.
Utilizing these specific data points allows the WCM platform to drastically reduce the number of potential content matches, which expedites the processing time and ensures the most relevant content is delivered to the user.
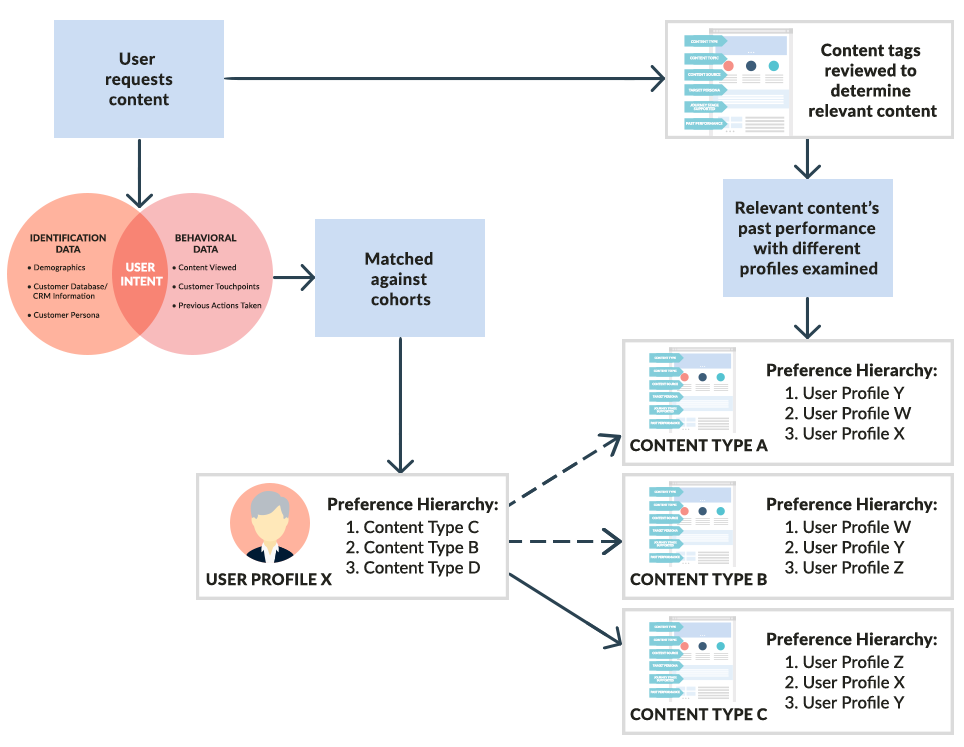
Your content analyst should review content performance to ensure that the most effective content is being served to the right profile. If it appears that the most effective content for a particular user profile is not the most commonly served, the content engineer should adjust rules to be sure this content is delivered more frequently. If these personalization rules have been configured correctly, then your platform will deliver the right content to the right users at the right time.
Related: What Is a Content Analyst?
So, what does it look like when all of these principles and practices come together?
Putting It All Together
To see what these principles look like in the real world, let’s take a look at Amazon.

Amazon’s level of personalization is simple and transparent. The online retailer only uses three pieces of behavioral data to customize its recommendations: the browsing and purchase history of the user, and the items they’ve added to their Wish List. The Wish List is a particularly valuable piece of functionality for Amazon’s data, as their WCM platform can prioritize these products over those that were merely just viewed. This makes creating a content preference hierarchy for an individual user extremely simple.
Customizations in design are also apparent. Each item listed as a recommendation for a certain user is a card, (a content component that serves as an entry point to more information). It’s essentially a thumbnail of a set height and width, allowing it to be easily switched out to match a different user’s preferences.
Amazon doesn’t stop there, though. Let’s look at some of the customized content on a product page.
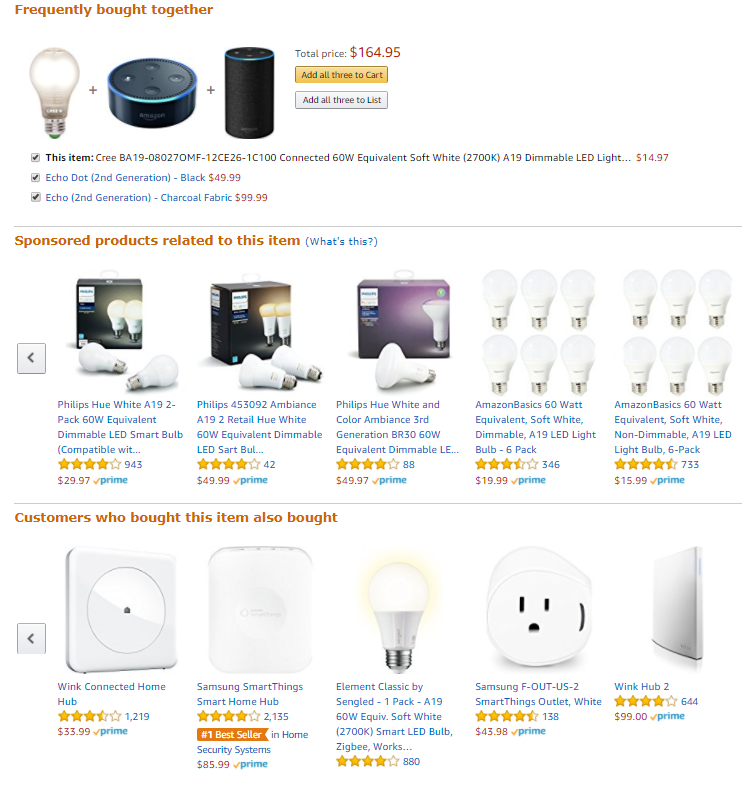
Here, we see the fruits of association rule learning and cohort analysis, as well as examples of treating every page like the homepage and providing the Best Next Customer Experience. Let’s look at the top row. Amazon has identified a group of items that are frequently purchased together across all user types. By analyzing all customer orders, they have found that these three items make sense to package into a single order, anticipating the user’s next step and maximizing the value of their visit.
The bottom row of suggested items shows that Amazon has analyzed the purchase history of users who have bought the product the user is viewing. By recommending these items to the user, Amazon is attempting to provide quick access to anything else the user may need to purchase. By ensuring the user’s visit to the site is targeted and efficient, Amazon is maximizing the usefulness of their content to the user.
As one of the biggest companies in the world, Amazon can offer this level of customization because of the tremendous amount of customer data they are able to leverage. Even if you don’t have this much data to play with, with the right team you can use the principles of design, data collection, and analysis to make your content feel just as personal.
In this article, we walked through how to get the right content team in place, designing your content for automation and personalization, incorporating data collection into your design, and applying concepts of machine learning to content delivery.
The Authors

Andrew Johnson is a former senior content analyst for Content Science, the end-to-end content firm company behind ContentWRX, Content Science Review, and Content Science Academy. Currently with The Home Depot, Andrew has worked with a wide range of organizations to define and measure content effectiveness and to empower enterprises with content intelligence. Andrew holds data and analytics certifications from leaders such as Google and the Digital Analytics Association.
Content Science partners with the world’s leading organizations to close the content gap in digital business. We bring together the complete capabilities you need to transform or scale your content approach. Through proprietary data, smart strategy, expert consulting, creative production, and one-of-a-kind products like ContentWRX and Content Science Academy, we turn insight into impact. Don’t simply compete on content. Win.




Comments
Love how this piece shows (very practically and specifically) how content engineering, artificial intelligence, and content intelligence are coming together. It’s an exciting time to do content.
Comments are closed.
We invite you to share your perspective in a constructive way. To comment, please sign in or register. Our moderating team will review all comments and may edit them for clarity. Our team also may delete comments that are off-topic or disrespectful. All postings become the property of
Content Science Review.